
How much testing is enough?
Or, where to draw the line when venturing down the QA rabbithole
So, you’ve written some code. Maybe it’s a single line of Perl. Maybe it’s the next big social network. Either way, you now have another concern before you ship it to production:
I want to make 100% sure my code works
Well, I have some bad news for you:
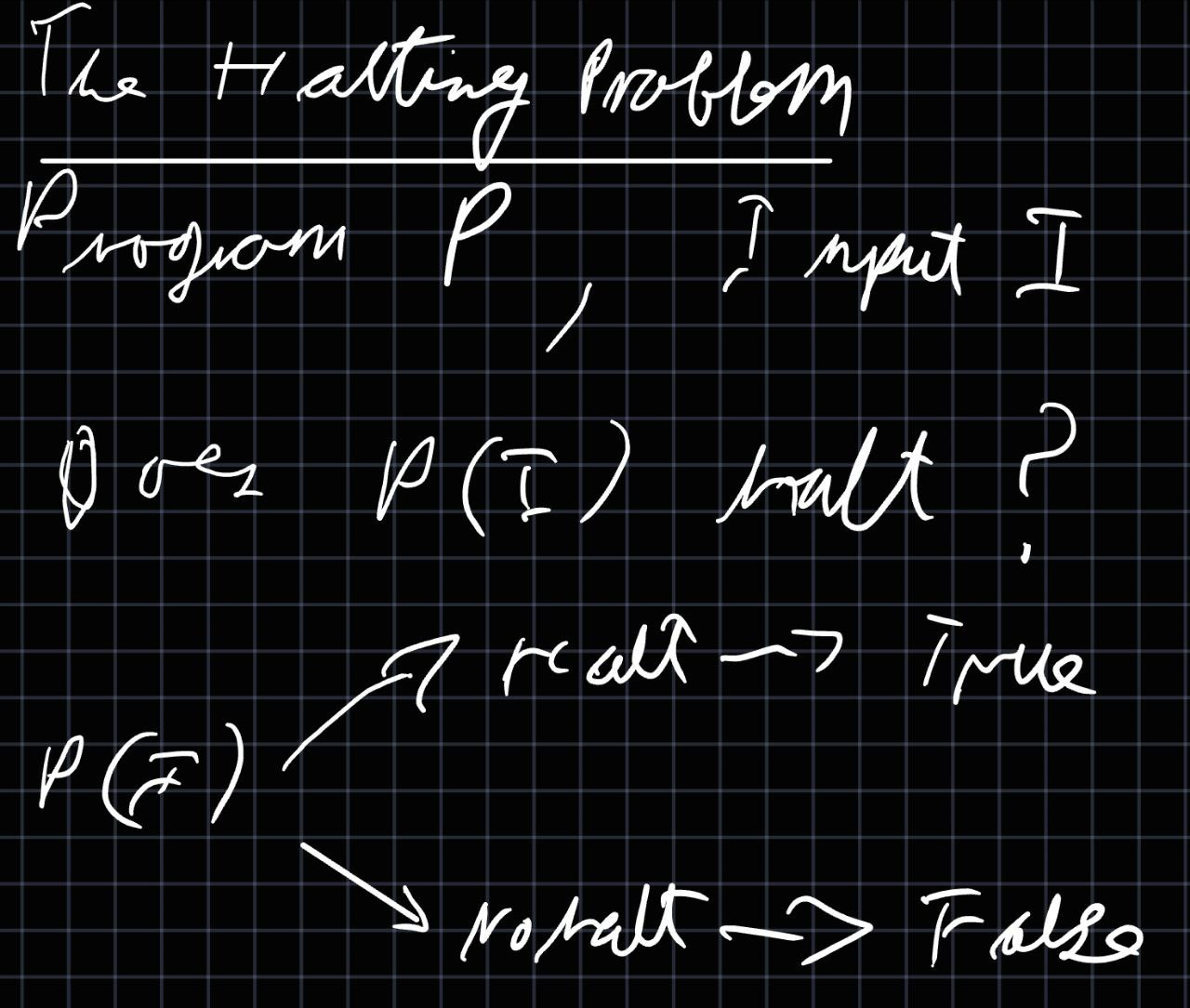
One of the implications of the Halting problem is that this is impossible (without the aid of some serious quantumn computing advances, anyway). You can dive into the theory here, but the short version is that the only way to ensure your program can handle every possible scenario is to run it against every possible scenario. In most cases that’s an infinite number.
Luckily, there’s another approach that’s absolutely possible:
I want to lower the risk that my code breaks
This is part of Quality Assurance, or QA. It consists of a range of activities designed to improve the quality of the final product. Testing usually forms a large component of QA, but it’s not the only one:

Peer/code review, chaos engineering, and even mathematical proof are all ways of improving the quality of the finished product. Most engineering teams use a combination of these - here’s why.
Test coverage
Imagine all the ways your code can break.

As explained above this is infinite, but we can imagine this square as representing the most likely group of issues. Now imagine your QA process as covering parts of that space. This is commonly referred to as QA or test coverage:
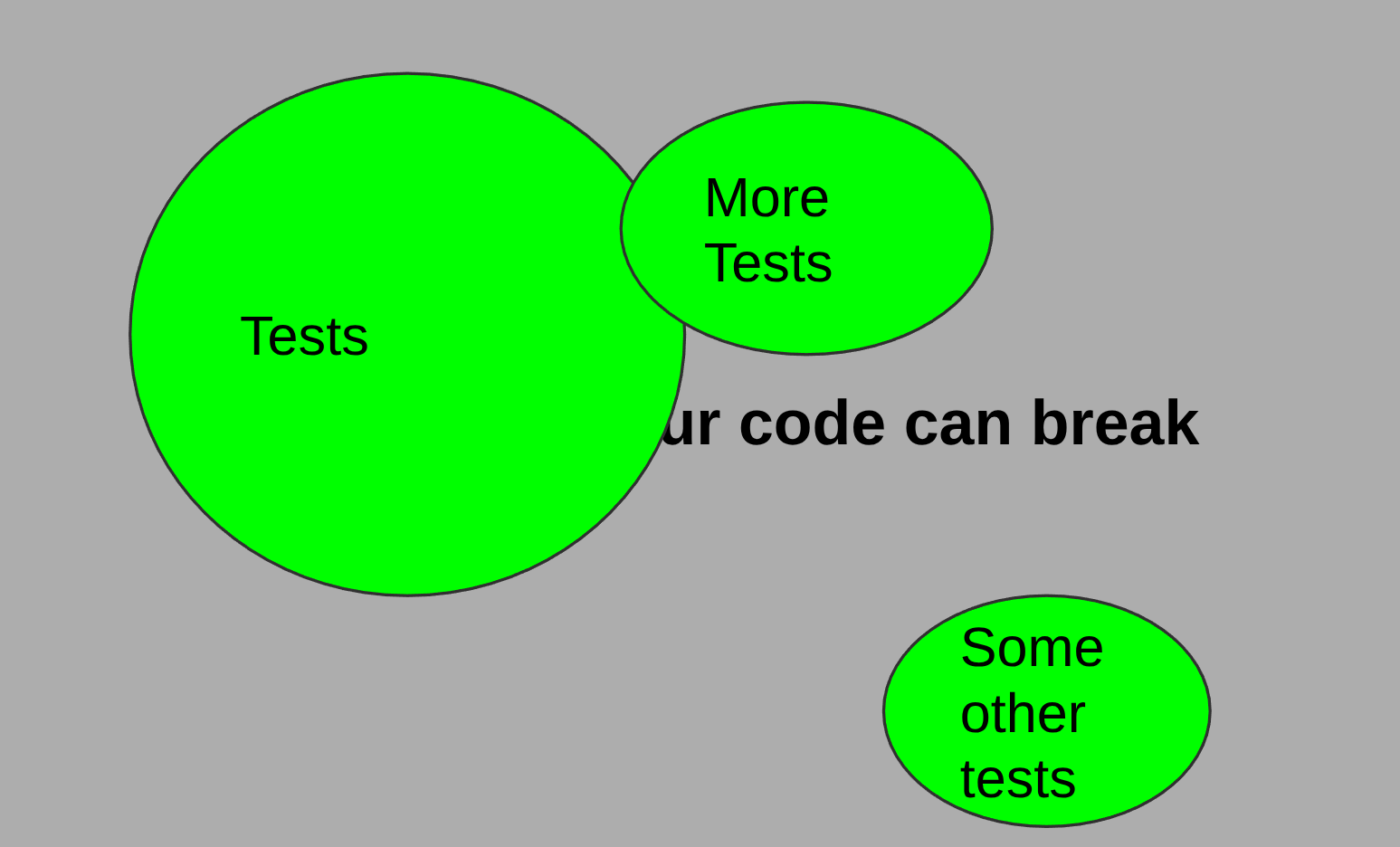
Each QA method covers a different range of possible scenarios, some of which will overlap. We can see that due to the infinite nature of possible issues it’s impossible to cover everything, but with enough QA coverage we can cover most if not all of the more common scenarios.
As you might expect, the more thoroughly you use a QA method the greater coverage it’ll give you, but after a while you get into diminishing returns. It’s a tradeoff - but one that we can take advantage of when using multiple QA methods:
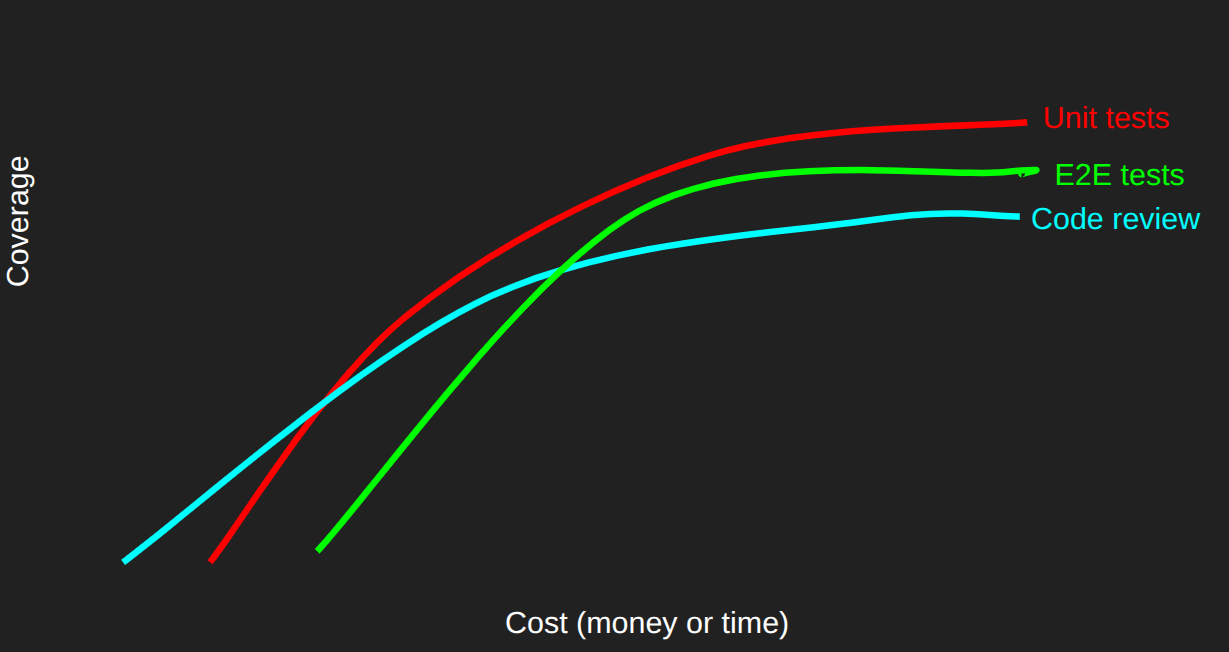
In order to optimise which methods we invest in, there’s a common strategy called the Test Pyramid.
The Test Pyramid
There’s 5 types of testing techniques that commonly make their way into software projects:
- End to end (E2E) tests: “Can I follow a full user journey from beginning to end?”
- UI tests: “Can I open the UI, press button X and see Y happen?”
- API tests: “Can I query an API, make X request and get Y back?”
- Integration tests: “Can I put X into a series of methods and get Y back?”
- Unit tests: “Can I put X into this method and get Y back?”
You’ll notice these are in an order. That’s because they’re a perfect example of tradeoffs between specificity, coverage and (computational) cost.
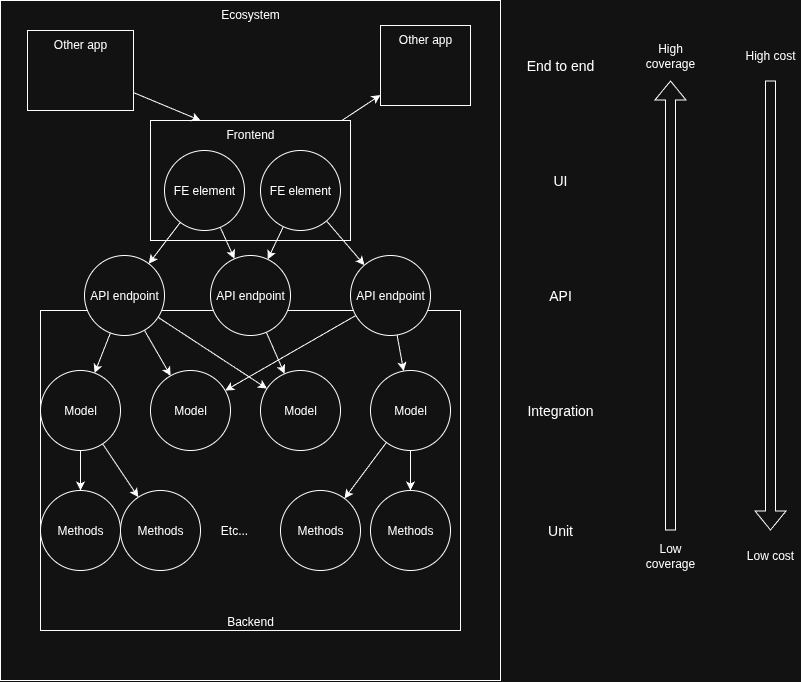
E2E tests, for example, cover a lot of code with each test because they interact with so many parts of the application in the process of following a user journey. The tradeoffs are that they require a full like-live environment to run on, and they can only tell you at a high level where the problems are (leaving the specific diagnosis to the engineer).
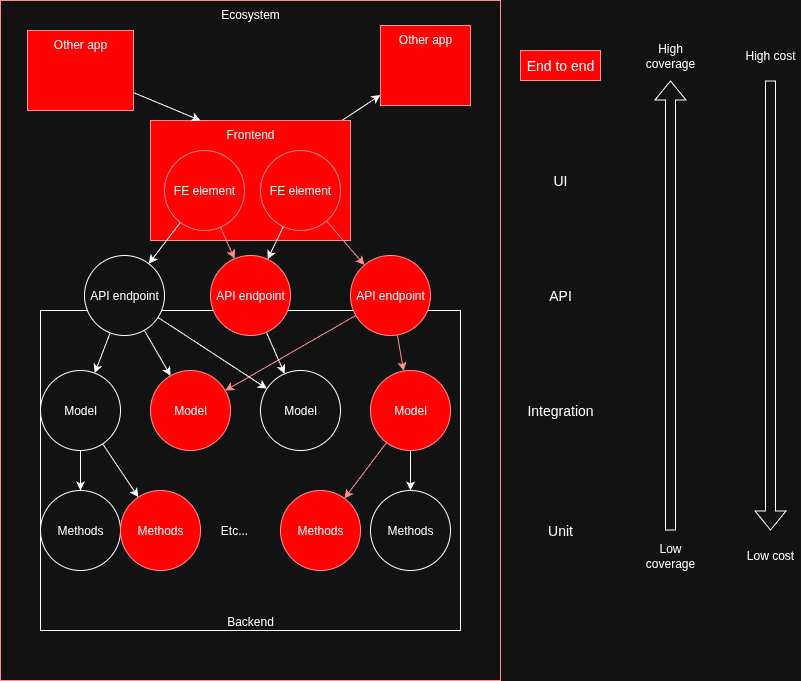
Unit tests, on the other hand, are popular because they’re quick to run and can tell you with much more precision where the issue in you code is. The disadvantage of course is that their low coverage means you need to write a lot of them in order to test your whole application.
So which ones to use and when? The test pyramid suggests a combination, but with some more than others. This is commonly visualised as a pyramid:

The strategy here is to have a few high coverage (but high cost) tests to cover the system as a whole, often run as a sense check before releasing live, coupled with more lower coverage (and lower cost) tests for more focused QA, often used for test driven development.
For example
Let’s consider a couple of examples to see how multiple QA methods combine their coverage:
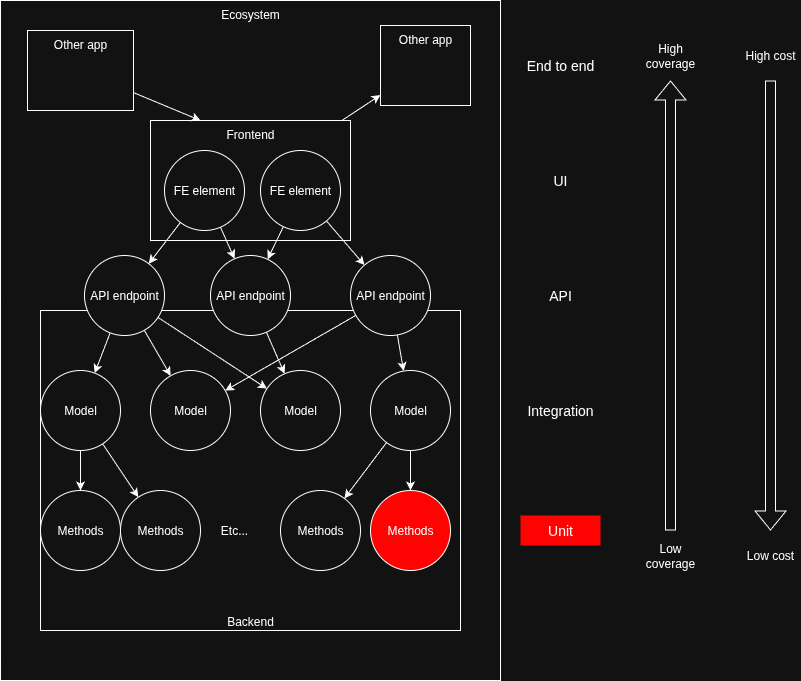
Example A: Test driven development
A team strictly adheres to the test driven development methodology, and always begin their work by writing unit tests. They’ve also written quite a lot of E2E tests, but didn’t get very far writing API tests. The Product Manager also does a cursory check of every release before it goes live, but tends to focus on the “happy path” scenario which is already covered by the E2E tests. After 6 months their test coverage looks like this:

Example B: Focusing on uptime
Another team made it their mission to make sure their application never has an outage (which is also impossible, but you can get close). They invested a lot of time into volume and performance tests, chaos engineering and security testing, which didn’t leave them as much time for writing unit tests. After 9 months, here’s their coverage:
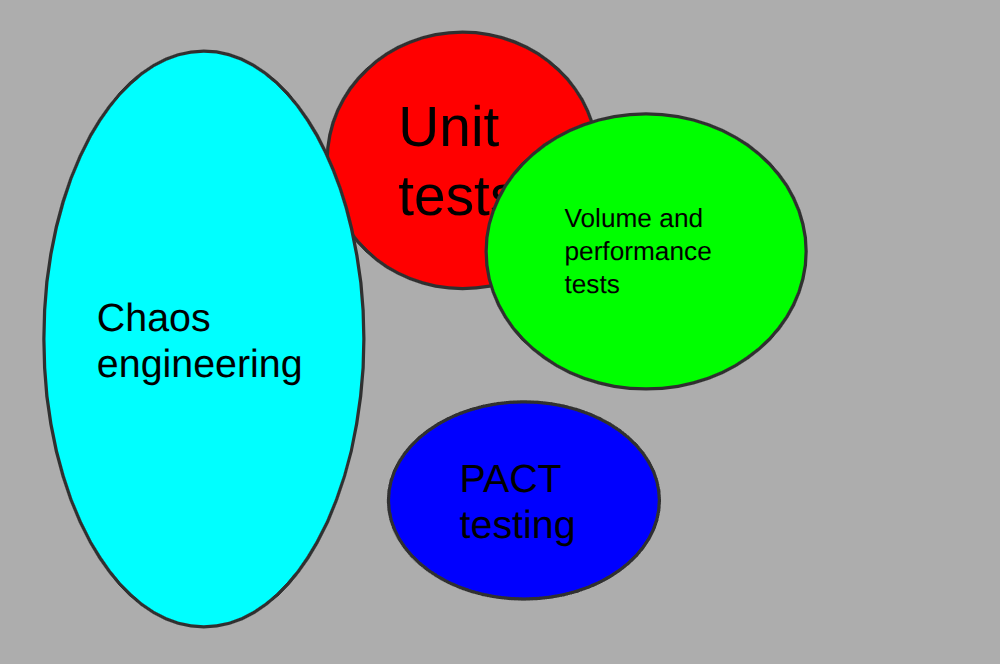
Which example is better? Example A more closely matches a typical product engineering team, and got there faster, but without knowing why B values uptime so highly it’s difficult to tell. It all depends on why you want to lower the risk.
How much QA is enough?
Now that we know how test coverage works, how much of it do we need? In order to know how much time to invest, we need to know more about why we’re building our application. A good question to ask is:
What happens if my code breaks?
Here’s some examples:
| Example | Impact | Cost |
|---|---|---|
| You’re experimenting with new technology in a sandbox | Nothing happens | 0 |
| An icon loads 1ms slower | Something happens, but it’s not noticable | 0 |
| One customer can’t place their order | Small loss of reputation/revenue | 💲 |
| No-one can place orders during a 1h outage | Medium loss of reputation or revenue | 💲💲 |
| All your customers payment data gets leaked | Major loss of reputation or revenue | 💲💲💲 |
| A self driving car crashes | Death or serious injury | 💀 |
| Skynet goes rogue and attempts to destroy humanity | Global thermonuclear war | 💀💀💀 |
Obviously the last two are quite extreme examples. If either apply to you, you probably want to be reading about safety critical systems rather than this article. For the rest of us, we can quantify the impact of broken code in terms of monetary cost:
Impact x Risk = Expected cost
QA allows us to lower this cost by reducing the risk:
(Risk - QA) x Impact + QA cost = Expected cost
We can use this formula to compare our QA strategies, and pick the one with the lowest overall cost.
For example
For simplicity, we’re going to assume someone’s time costs $100/day.
Example A: Legacy system report
An report in a legacy system is used once in a blue moon. If it breaks it’d mean an analyst need to spend a day writing a new report.
Impact: 1 day analyst time
Risk: 10% chance it happens in the next 5 years
We can now compare options:
| Option | Risk reduction | QA time | Expected cost |
|---|---|---|---|
| No QA | None | None | $100 x 0.1 = $10 |
| A few UI tests | 99.9% | 1 day | $100 x 0.001 + $100 = $100.10 |
| 80% unit test code coverage | 99% | 5min | $100 x 0.01 + $5 = $6 |
| Overanalyse the performance benchmarks | None | 5 days | $100 x 0.1 + $500 = $510 |
The cheapest option here is to write a few quick unit tests, although for a saving of $4 there’s probably higher priorities in the real world, in which case we simply accept the risk and move on. It also shows that not everything will have an impact - performance benchmarks mean very little if that’s the only QA you do!
Example B: Apollo 11 guidance system
Let’s say you’re writing the guidance system for Apollo 11. If it goes wrong the rocket will crash.
Impact: $288 billion rocket + certain death + international headlines
Risk: 90% chance it happens during the mission
Therefore, you and the folks at NASA will be comparing something like this:
| Option | Risk reduction | QA time | Expected cost |
|---|---|---|---|
| No QA | None | None | $288bn+ x 0.9 = $259bn+ |
| 100% unit test code coverage | 50% | 1 month | $288bn+ x 0.5 + $3000 = $ Still too high |
| Component tests, manual testing, mathematical proofs, peer review, thermal analysis, performance testing, end to end testing in the rocket… | 99.99999% | Several teams working for years | $288bn+ x 0.0000001 + $1bn = Roughly $1.3bn |
The cost of failure here is so high that spending billions of dollars to lower the risk as much as possible is easy to justify. Unit tests alone aren’t going to cut it!
In the real world
Real life is never this simple. Here’s some of the other things to consider:
Estimation is hardly ever accurate
This applies to both risk and time - that impossible edge case that could never happen is guaranteed to happen as soon as you ship your code. Conversely, the 5min unit test you’d need to avoid it may end up taking hours to write.
Impact and risk will change over time
No application exists in a vacuum (well, except the Apollo guidance system above). Quick and dirty Excel spreadsheets can suddenly find their way into an entire country’s Covid reporting, while unreliable legacy systems get replaced with more reliable ones.
Good tests speed up development
Test driven development helps you write better code to begin with, and also speeds up maintenance when you need to add a new feature or debug an issue. It’s not just about lowering risk!
Not all tests provide useful coverage
A few examples here have alluded to this - there’s no point load testing an application that’ll never experience high load!
Not all test scenarios are obvious
This is why testing is such a fine art - if all the cases were obvoius we would have automated it already!
Testing is hard!
It really is! If you’re finding it easy, you’ve probably missed an edge case somewhere.
Lowering the impact is always another option
The other part of the QA formula is cost of something going wrong - lower it and you can get away with less QA. Switching off unused functionality, implementing a failsafe, or even taking out an insurance policy (yes, this is a thing) can lower the cost if something goes wrong.
So how much QA is enough?
In most engineering teams QA consists a code review process, >90% unit test coverage with test driven development, plus one or two method(s) from further up the test pyramid to ensure everything ties together properly. Beyond this default option, your QA should be:
Enough that you are okay with the risk and impact